[mtype] タイピングソフトを作るには
公開中のタイピングソフトmtypeは、1つの問題文データでローマ字入力・かな入力の両方に対応しています。また、ローマ字入力についてはMS-IMEの標準設定でサポートする入力パターン全てに対応しています(例えば「く」は「ku」「cu」「qu」のどれでも使えます)。
※画面上に表示するローマ字入力パターンは1つ(「く」なら「ku」)ですが、それに沿ってなくても入力は可能です。
一方、世の中にあるタイピングソフトの中には、ローマ字入力専用だったり、ローマ字入力・かな入力でプログラムが別だったり、ローマ字入力で使えるパターンが限定されているものもあります。
ここでは、プログラム言語に依存しない形で、mtypeで作ったロジックについて説明します。
なお、ここでは問題文として「漢字かな混じりフレーズ(表示用)」と「読み仮名」の両方が揃っているものとします(mtypeでは、問題文を集めたテキストファイルの各行は、表示用フレーズと読み仮名をタブで区切った形です)。読み仮名を自動で求めるプログラムもありますが、読み仮名に間違いがあるとタイピングソフトとしては困るので。
※以下の記述では、ローマ字かな変換の規則としてMS-IMEの標準設定を前提とします。
ローマ字入力:問題の捉え方
タイピングソフトでは、打鍵の瞬間にパターンが正しいか判定できる必要があります。英語なら問題文とタイピング時の入力は1対1で対応できるので簡単ですが、日本語の場合、少なくともローマ字入力・かな入力の両方に対応したいところですし、ローマ字入力は複雑です。
例えば「わたしはちゃっとさんだん」というフレーズの場合。
冒頭の「わた」は「wata」だけが正解なので簡単ですが、次の「し」は「si」でも「shi」でも打てますし、さらに「ci」でも打てます。
次の「ちゃっと」は「chatto」でも「tyatto」でも「tixyaltuto」でも打てます。たくさんのパターンがありそうです。
最後の部分「さんだん」の場合、例えば「Sandann」と打てば、最初の「ん」は「n」1回で出ます。しかし最後の「ん」は「nn」とか打たないと出ません。また、語中でも「こんな」は「konnna」と打つと「n」が3つ続きます。

ローマ字入力を整理すると、次のような複雑さがあることが分かります。
- かな文字1つに対してでも、複数のパターンがありうる(「く」は「ku」「cu」「qu」のいずれでも入力できます)
- かな文字複数に対して、特有のパターンがありうる(「ちゃ」は「cha」などの一括パターンと、「tixya」などの文字ごとに分解するパターンがあります)
- 「っ」の後に「aiueon」以外が来る場合、「っ」の直後のパターンの先頭文字を重ねることで「っ」も入力できる(「かった」は「kaxtuta」「kaltuta」以外に、もっと短く「katta」などで入力できます)
- 「ん」の後に「aiueony」以外が来る場合、「ん」は「n」1回で入力できる(「かんだ」は「kannda」や「kaxnda」以外に、もっと短く「kanda」などで入力できます)
そして、タイピングソフトである以上、入力中のパターン(の例)を、ガイドとして表示したいところです。しかも、そこまでの打鍵結果によっては、表示すべきパターンに制約がつきます。
例えば、入力すべきフレーズが「ふぃ」だった場合。ちょっと考えれば次のようなケースが考えられます。
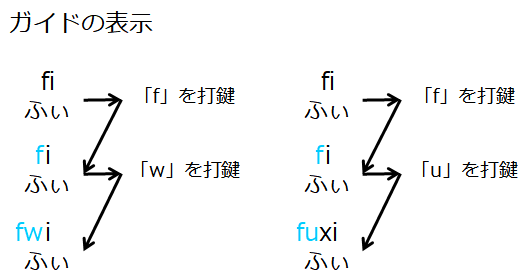
- 最初は最短パターンである「fi」が表示されてほしい
- 「f」か「h」以外を打鍵した場合は、ミスタイプとして判定したい
- 最初の打鍵が「f」だった場合、表示するパターンは「i」になる
- 最初が「f」で次が「i」なら、「ふぃ」は完了なので、次に進む
- 最初が「f」で次が「w」だった場合、「ふぃ」を「fwi」で入力するパターンなので、表示パターンは依然として「i」となる
- 最初が「f」で次が「u」だった場合、「ふ」と「ぃ」を分けて入力する前提となるので、表示パターンは「ぃ」に対応する短いパターンの「xi」か「li」であるべき(「xyi」「lyi」は「ぃ」の長いパターン)
- 「h」を打鍵した場合は、「ふ」と「ぃ」を分けて入力する前提となるので、表示するパターンは「uxi」か「uli」に切り替える必要がある
ローマ字入力:入力文字列を分解する
ここまで、ローマ字入力に関連する煩雑さを整理しました。次は対策です。
まず、複数の入力パターンがある場合については、「{ "か" , { "ka" , "ca" } }」という感じで、かな文字に対して複数のパターンを準備すれば対応できそうです。
一方、「っ」や「ん」が関わると、ややこしくなります。
ややこしさを低減するには、考える範囲を狭めるのが有効です。そこで、入力された文字列(問題文の「読み仮名」)を、「独立した最短の部分」に分解します。それぞれの部分ごとに考えていけば整理しやすくなりそうです。
例として「こんなびっくりげんしょう」を取り上げます。
(このフレーズは「っ」と「ん」を含み、なおかつ「ん」は短縮パターンが使えるもの(「げんしょう」の「ん」)と使えないもの(「こんな」の「ん」)があります。また、2文字の短縮パターン(「しょ」)もあるものです)
分解に際して、ここまで考えてきたことを改めて示します。
- 通常は、かな1文字に対して1つ以上の打鍵パターンが決まる
- かな2文字に対して固有の短縮打鍵パターンが使える場合がある
- 「っ」の後に来る文字次第では、短縮打鍵パターンが使える場合がある
- 「ん」の後に来る文字次第では、短縮打鍵パターンが使える場合がある
これらを全て考慮すると、次のように分解できます。
「こ/んな/び/っく/り/げ/んしょ/う」
「しょ」に短縮パターンがあること、「っ」や「ん」は後の文字と組み合わせて短縮パターンができる場合があることから、このような結果になります。
この分解の利点は、「ある部分は他の部分とは独立に打鍵パターンが決まる」ことです。その部分の中には複数のパターンがありますが、前後の部分とは無関係なので、部分ごとにパターンを列挙していけばいいのです。
例えば冒頭の「こ」。「ko」と打っても「co」と打っても、次の「ん」の打鍵パターンとは無関係です。「ん」を「nn」と打つか「xn」と打つかも、「こ」とは無関係です。つまり、組み合わせを考慮する必要がありません。
もし、「びっくり」を「び/っ/く/り」と分割すると、「っ」の打ち方は「く」の影響を受けてしまいます。これだとややこしくなってしまいますよね。
例の区切り方で最も長いのは「んしょ」ですが、これも「んしょ」の内側では複数の候補があるものの、前後の「げ」や「う」とは互いに無関係です。そして「んしょ」を複数に分割すると、前後で干渉してしまいます。
ちなみに、mtypeでは、この分解結果を表すために「Chunk」(英語で「かたまり」)というクラスを作りました。ここでも、この分解結果を「チャンク」と呼ぶことにします。
チャンクの分割は、mtypeでは次のように行っています。ローマ字かな変換パターンを基準としつつ、前から「っ」「ん」がある場合は、その次のパターンとつなげたものをチャンクとします。
- 先頭から順番に文字を調べていく
- 現在見ている位置の文字が「っ」か「ん」なら次の文字を起点、それ以外なら現在見ている文字を起点とする
- もし起点からの2文字にローマ字かな変換パターンがあれば、その2文字(手前に「っ」「ん」がある場合はそれも)をまとめてチャンク化
- なければ、起点の1文字(手前に「っ」「ん」がある場合はそれも)をチャンク化
- チャンク化した文字を飛ばして、その次の字を「現在見ている位置」として繰り返し
「こ/んな/び/っく/り/げ/んしょ/う」の分割を図にしてみました。

ちなみに、「っ」や「ん」が続いた場合ですが、上の方法で機械的に処理するだけです。
例えば「んんんん」なら、最初の「ん」を見て次の「ん」とつなげてチャンク化、次に3つめの「ん」を見て次の(4つめの)「ん」とつなげてチャンク化します。つまり「んん」+「んん」ですね。
「んん」は最短だと「nxn」で入力できます。その調子で「nxnxnxn……」と続けても「んんん……」と打てますが、多数の「ん」でも「nxn」を繰り返した方が少ない打鍵で打てます(「nxnxn……」は結局4打鍵目から「xn」を繰り返し打つので1/2[字/打]なのに対して「nxn」は常に2/3[字/打]だから)。
「っんんっ」なら、「っん」+「んっ」の2チャンクです。「xxnnxtu」などが短いですね。
「っっっっ」なら「っっ」+「っっ」の2チャンク。「xxtuxxtu」などが短いですね。なお、「っ」の連続はIMEによっては子音字を連打するだけで出るようですが、MS-IMEでは通用しません。mtypeでもこのパターンには対応していません。

ローマ字入力:打鍵パターンを求める
次に、チャンクごとの打鍵パターンを求めます。ここでの打鍵パターンは、ローマ字入力なら、チャンクの文字列に対応するローマ字の並びです。先ほどの例の最初のチャンクは「こ」ですが、これに対応する打鍵パターンは「ko」か「co」の2つです。
チャンク先頭に「っ」や「ん」がない場合、かな文字と対応する打鍵パターン群をマッピングしたデータが利用できます。一方、「っ」や「ん」がチャンク先頭にある場合、打鍵パターンの組み合わせを考慮する必要があります。
例えば、チャンクのメイン部分が「か」だった場合、次のような打鍵パターン群が発生します。
- 「っ」「ん」の影響のない場合:事前準備したデータそのまま(「か」に対しては「ka」「ca」)
- 「っ」が関わる場合:「っ」の次の子音を重ねたものと、「っ」と次の部分を独立に入力する組み合わせの両方
(「っか」に対しては前者が「kka」「cca」の2件、後者が「xtuka」「xtuca」「ltuka」「ltuca」「xtsuka」「xtsuca」「ltsuka」「ltsuca」の8件) - 「ん」が関わる場合:「n」を先頭につけたものと、「ん」と次の部分を独立に入力する組み合わせの両方
(「んか」に対しては前者が「nka」「nca」の2件、後者が「nnka」「xnka」「nnca」「xnca」の4件)
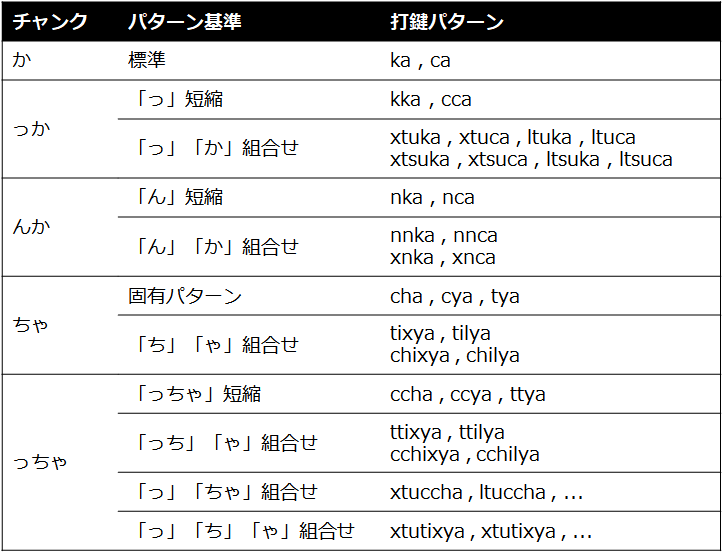
mtypeでは、次のような扱いです。
- 先に示した、MS-IMEのローマ字かな変換パターン相当の情報は、デフォルトとしてハードコード
- 前項目のうち、かな2文字を一気に打つパターン(「っ」「ん」を含まないもの)については、1文字ごとのパターンの組み合わせも必要なので、最初に動的生成(「ちゃ」なら「ち」「ゃ」の組み合わせ)
- 「っ」や「ん」の処理は、チャンクごとの打鍵パターンを求める時に動的生成
mtypeでは、MS-IMEのローマ字かな変換パターン相当の情報はRomanInputというクラスにまとめておき、同時に入力フレーズ(の読み仮名)をチャンクに分解するメソッドももたせています。これは、チャンクへの分解時にローマ字かな変換パターン(のうち、かな部分)が必要なためです。
また、先ほど述べたChunkクラスには、当該チャンクの読み仮名と、対応する打鍵パターン(TypePatternクラスのオブジェクト)のリストを保持しています。
例えば、「んか」というチャンクは、読み仮名(「んか」)と、打鍵パターンとして「nka」「nca」「nnka」「xnka」「nnca」「xnca」の6件を保持しているわけです。
ローマ字入力:入力の判定
ローマ字入力の場合、打鍵はローマ字(や数字、記号)に変換されます。あとは、いま打鍵中のチャンクに対して、合っているか判定させられます。
先の「んか」というチャンクを例にとります。
最初の打鍵結果として「n」が来た場合、内部の打鍵パターン6件の先頭の文字と比較すると、「nka」「nca」「nnka」「nnca」の4件がマッチします。したがって、判定結果は「正しい打鍵」、そして内部でマッチしなかった「xnka」「xnca」を省いて、他は打鍵パターン内部のインデックスを(0から1に)進めた上で、次の打鍵を待ちます。
次に「n」が打鍵された場合、打鍵パターンのうち「nnka」「nnca」の2件が残ります。最初と同様に処理します。
次に、もう1回「n」が打鍵された場合、残った2件の打鍵パターンは既にインデックスが2(「k」または「c」)なのでマッチなしとなります。この場合は判定結果「ミスタイプ」として、各打鍵パターンのインデックスは変わらず、次の打鍵を待ちます。
ローマ字入力:打鍵パターンをガイドとして表示する
タイピングソフトなら、次に打鍵すべきパターン(の例)をガイドとして示したいところです(直前の例なら、「んか」というチャンクに対して「n」を打った直後は「ka」あたりがガイド表示)。
前で書いた判定方法だと、ある時点で有効な打鍵パターンはチャンク内に保持されているので、そのうち1つを取り出して、全ての(打鍵が終わっていない)チャンクについて連結して表示すればガイドになります。
判定とガイドについて、図(?)にしてみました。

かな入力の処理
かな入力は、多くの文字が打鍵と1対1です。その例外となるのは濁点や半濁点だけで、これらも決まったパターンなので、とても簡単です。
ただ、チャンクへの分割や、チャンクごとの打鍵パターンといった形式はローマ字入力と同様に(主にインタフェースを通じて)もたせます。これによって、タイピング関連ロジックをローマ字入力・かな入力の差なく呼び出すことが可能となります。

打鍵の扱い
ローマ字入力でも、かな入力でも、キーを打った時に何のキーなのかを取得する必要があります。ローマ字入力だと、打鍵時に処理側で取得できる情報に、キーに対応するローマ字情報が含まれることが多いのですが、かな入力の場合の対応は、何らかのテーブルをもつ必要があります。また、ローマ字入力でも、米国配列のキーボードもありますし、キーボードの刻印を無視してDVORAK配列など他の並びとみなして入力する人もいるでしょう。
ですから、打ったキーのキーコードから、打ったとみなす文字(ローマ字なら英数字など、かな入力はかな文字も含みます)を求める部分は、交換可能なテーブルにすることが望ましいところです。
mtypeでは、日本語を使う環境で最も標準的と思われる109Aキーボードのローマ字入力、かな入力のキー対応テーブルを、KeyManagerクラスとしてもっています。
まとめ
日本語のタイピングソフトで、かな入力・ローマ字入力を扱うための設計例として、mtypeでの設計の考え方を示しました。
問題文を選択した時、読み仮名を、互いに干渉しない単位「チャンク」に分割し、チャンクごとに1件以上の打鍵パターンを求めます。
一方、打鍵時にはキーコードから打鍵パターン上の1文字に変換し、現在のチャンクの打鍵パターン群で結果を判定します。

この方法は比較的シンプルなので、多くの言語やシステムで動作するものと考えています。
◀(前記事)[MP02] mekikuプロトコルとIPtalk互換プロトコルの概要
▶(次記事)[PC一般]Outlook(アウトルック)で送られたメールの添付がおかしい件
(一覧)[2.技術情報 (tech)]